Korelasyon analizi, sayısal değişkenler arasındaki ilişkinin yönünü ve derecesini tespit edebilmek için kullanılan bir istatistiksel yöntemdir. Korelasyon analizindeki en önemli nokta, nedensellik ilişkileri Bugün birçok bilim dalında yürütülen çalışmada korelasyon analizi uygulanmaktadır. Yalnız korelasyon analizi uygulanırken teorik düzeyde bazı kavramlara dikkat edilmediği için hatalı sonuçlar elde edilmektedir. Korelasyon analizi uygulanırken dikkat edilmesi gereken iki temel nokta var:
· Değişkenlerin dağılım şekli
· Korelasyon katsayısının anlamlılığı
Korelasyon analizine başlamadan önce ilk yapılacak şey değişkenlerin normal dağılıp dağılmadığını belirlemektir. Normal dağılan değişkenler için literatürde en sık kullanılan teknik Pearson korelasyon katsayısıdır. Normal dağılıma uygun olmayan değişkenler için Spearman korelasyon katsayısı kullanılır. Uygun korelasyon analizi belirlendikten sonra, değişkenler arası doğrusal bir ilişkinin olup olmadığını belirlemek üzere korelasyon katsayısı için anlamlılık testi yapılmalıdır. Bu testin uygulanması son derece akla uygundur. Çünkü iki değişken arasında doğrusal bir ilişki yoksa, korelasyon katsayısı 0.99 dahi olsa bir anlam ifade etmez. Özellikle örnek sayısı çok düşük olduğunda, korelasyon katsayısı yüksek çıkabilmektedir. Elimizde yeteri kadar bilgi olmaması sebebiyle bu durum yanıltıcıdır.
Bu yazımda R programı kullanarak sayısal değişkenler arasındaki korelasyon değerlerini görsel olarak gösteren bir program yazdım. Programın içerisinde kofgrafik( ) isimli bir fonksiyon var ve bu fonksiyonun içerisine veri setinin adını yazdığınız zaman size değişken sayısı kadar çokgen oluşturuyor. Her değişken isminin ilk dört harfi çember biçimindeki değişkenlerin içerisine otomatik olarak yerleşiyor. Bu deneme asıl çalışmakta olduğum Bayesci ağlar (Bayesian network) konusu için bir temel oluşturmak üzere yapılmıştır. Ayrıca R programının ne kadar güçlü bir program olduğunu göstermek üzere çarpıcı bir örnektir. Çünkü SPSS, Minitab gibi programlarda sadece menüler aracılığıyla analiz yapabiliyoruz ve bu durumda paket programa tam anlamı ile mahkum oluyoruz. Akademik kariyer düşünen her istatistikçi mutlaka bir programlama diline hakim olmalı ve kendi programını kendi yazmalı. Ancak bu şekilde ortaya yeni bir şeyler koyabilir. R programı, açık kaynak kodlu ve ücretsiz olduğu için severek kullanıyorum, analize doğrudan müdahale edebilmek inanılmaz keyif veriyor. Her istatistikçinin kullanmasını şiddetle öneriyorum.
Bu kadar R övgüsünden sonra grafiği tanıtacağım. Grafiğin yorumlanması son derece basit. Her değişken bir düğüm (çember) şeklinde gösteriliyor. Her çemberin içinde değişkenin ilk dört harfi gösteriliyor. Değişkenler arasındaki korelasyon katsayısının anlamlı olması durumunda, değişkenlerin normallik durumuna ve korelasyon derecesine göre bir çizgi çekiliyor. Grafikte iki düğüm arasına, korelasyon katsayısı anlamlı olduğunda ve değişkenler normal dağılıma uyduğunda değişkenler için düz çizgi çekiliyor. Normal dağılış göstermeyen ve anlamlı korelasyon içeren değişkenler için noktalı çizgi çekiliyor. Korelasyon katsayısı 0.80 ve üzerinde ise çizgi lacivert, 0.60-0.80 arasında ise sarı, 0.60 ve altında ise turkuaz renkle gösteriliyor. Bu yazdığım lacivert, sarı ve turkuaz çizgiler sadece aynı yönlü ilişkili değişkenler için geçerli. Zıt yönlü ilişkili değişkenler kırmızı çizgi ile gösteriliyor. Çizginin kalınlığına göre korelasyonun yüksek olup olmadığını anlayabiliyorsunuz.
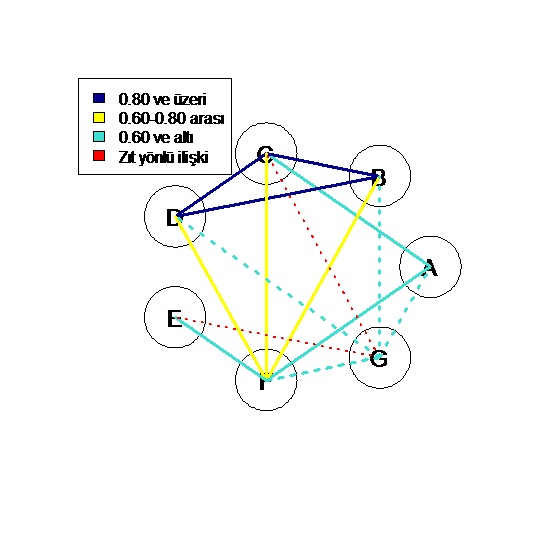
Yukardaki grafik korelasyon ilişkilerini net bir biçimde gösteriyor. R programının bnlearn paketinde yer alan “gaussian.test” veri seti kullanılarak, sekiz değişken arasındaki ilişki dereceleri ve yönleri gösteriliyor. Fonksiyon korgrafik(“gaussian.test”) biçiminde kullanılıyor. Fonksiyonun içerisine veri setinin adının yazılması yeterli, grafik değişken sayısına uygun bir çokgen biçiminde oluşturuluyor. Burada 7 değişken olduğu için yedigen şeklinde bir çizim görüyoruz. Kodlarını açık açık burada paylaşmadım. Bu grafiğe bakarak (C,D) ve (C,B) değişkenleri arasında aynı yönlü veya yüksek düzeyde bir ilişki olduğunu saptayabiliyoruz. (E,G) ve (C,G) değişkenleri arasında zıt yönlü ve düşük dereceli bir ilişki var. Ayrıca bu çiftler için Spearman korelasyon katsayısı kullanılmış, çünkü kesik çizgiler çizilmiş. Aşağıda bir örnek daha var. Bu örnek de R programının içerisinden bulunan "infert" isimli veri setini içeriyor. Sadece korgrafik("infert") yazmak yeterli.
